annbatch#
A data loader and io utilities for mini-batched data loading of on-disk anndata files,
co-developed by Lamin Labs and scverse.
annbatch lets you train models on terabyte-scale collections of AnnData files that do not fit
into memory, while keeping your GPU fed with high-throughput, shuffled mini-batches by doing chunked fetching (similar to Nvidia’s Merlin or webdataset). It also supports in-memory data.
Note
You can also use the annbatch.Loader on raw zarr.Array objects via add_datasets() if your object does not fit the anndata.AnnData class object cleanly, as long as the data is semantically row-wise oriented on-disk.
The annbatch.Loader.__iter__() fetching of (contiguous) data is simply done along the first (0th) axis of your data i.e., on-disk zarr with potentially more than two dimensions.
See the single-cell microscopy images tutorial for an example that streams a 4-dimensional image stack this way.
AnnData simply provides a convenient wrapper for providing annotated data with two dimensions.
Note that the preshuffler DatasetCollection requires AnnData inputs, and that preshuffling is highly recommended for top performance.
If you have genetics data, see cellink for info on converting to anndata.
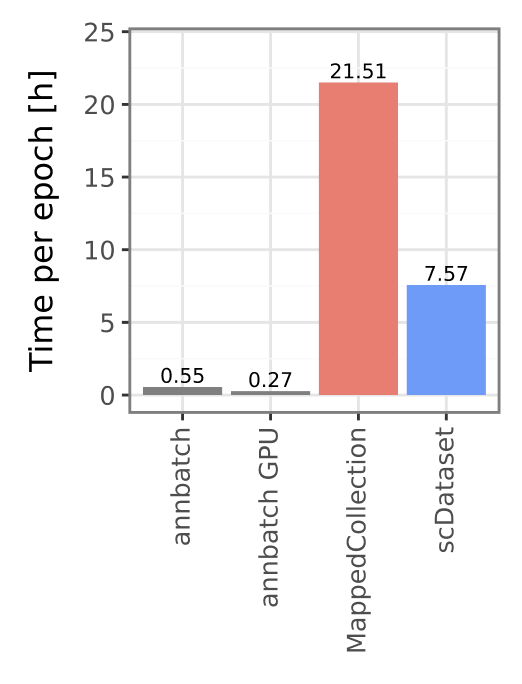
New to annbatch? Check out the installation guide and pick the right extras.
A hands-on notebook: convert your .h5ad files and stream shuffled mini-batches.
End-to-end runnable tutorials: scRNA-seq, genetics (VCF), microscopy images, and multi-GPU training.
An in-depth tour of preprocessing, chunked loading, sampling and benchmarks.
The API reference contains a detailed description of the annbatch API.
Need help? Reach out on the scverse forum to get your questions answered.
Found a bug? Interested in contributing? Check out the source on GitHub.
Citation#
If you use annbatch in your work, please cite the annbatch publication:
annbatch unlocks terabyte-scale training of biological data in anndata
Gold, I., Fischer, F., Arnoldt, L., Wolf, F. A., & Theis, F. J. (2026). annbatch unlocks terabyte-scale training of biological data in anndata. arXiv. https://doi.org/10.48550/arxiv.2604.01949
@article{Gold_2026,
author = {Gold, I. and Fischer, F. and Arnoldt, L. and Wolf, F. A. and Theis, F. J.},
title = {annbatch unlocks terabyte-scale training of biological data in anndata},
journal = {arXiv},
year = {2026},
doi = {10.48550/arxiv.2604.01949},
eprint = {2604.01949},
archivePrefix = {arXiv},
url = {https://doi.org/10.48550/arxiv.2604.01949}
}